今日 AI 早報:AMD 推出 Ryzen AI Halo 開發者平台!128GB 統一記憶體挑戰本地端 AI 霸權
AMD 於六月中旬正式開放預購首款 Ryzen AI Halo 開發者平台(售價 3,999 美元),配備 16 核心 Zen 5、40-CU 的 Radeon 8060S GPU 與 128GB LPDDR5x 統一記憶體,為本地端 Agentic 工作流提供全新選擇。
前言
隨著本地端 AI 模型與 Agentic 工作流(智慧代理工作流)的爆發性成長,開發者對於本地端顯示記憶體(VRAM)容量的需求已經達到前所未有的高度。
過去,若想要在本地端流暢運行超過 70B(700 億參數)的開源大型語言模型(LLM),蘋果(Apple)的 Mac Studio 或配備大容量統一記憶體的新款 MacBook Pro 幾乎是開發者唯一的選擇。
然而,AMD 最近推出了全新的「Ryzen AI Halo 開發者平台」,並正式開放預購(售價 3,999 美元)。這款迷你電腦(Mini PC)搭載了驚人的 128GB LPDDR5x-8000 統一記憶體,直接挑戰蘋果與 NVIDIA 在本地端 AI 推論市場的霸權。
AMD Ryzen AI Halo 開發者平台本地運行大語言模型與智慧代理工作流展示影片
核心規格:Ryzen AI Max+ 395 的怪獸級效能
這款被稱為「Ryzen AI Halo」的開發者套件,核心是 AMD 最新旗艦級 APU 晶片(代號 Strix Halo),正式命名為 Ryzen AI Max+ 395。
其硬體配置非常強大:
- 處理器:擁有 16 個 Zen 5 架構的 CPU 核心。
- 顯示核心:整合了高達 40 個 Compute Units (CU) 的 Radeon 8060S iGPU(基於 RDNA 3.5 架構)。這個顯示核心的效能表現已經能媲美中高階的獨立顯示卡。
- 統一記憶體:配備 128GB LPDDR5x-8000 統一記憶體。與傳統 PC 架構不同,這 128GB 記憶體是由 CPU 與 GPU 共享的。這意味著 GPU 可以直接調用極大容量的記憶體作為顯示記憶體(VRAM),用以載入超大型的 AI 模型。
- NPU(神經網路處理器):提供 50 TOPS 的本地端 AI 算力。
軟硬體一體化:從創意到工作流僅需數分鐘
為了解決 AMD 在 AI 軟體生態上一直以來的相容性痛點,這款開發者平台在出廠時就做好了軟硬體的高度整合:
- ROCm 軟體棧預裝:系統已預先配置好 AMD 自家的 ROCm 開源軟體棧,提供一流的生成式 AI 效能與 Day 0 支援。
- AI Playbooks 與開發者中心:預裝「Ryzen AI Developer Center」中心化應用,提供預先配置的 AI 劇本(AI Playbooks),讓開發者在開機後數分鐘內即可在本地端載入大語言模型、啟動程式開發助理、圖像生成或自動化流程。
- 多系統支援與免除雲端成本:提供 Windows 11 Pro 或 Linux 兩種系統版本選擇,開發者可自由在本地部署和管理最高達 200B 參數的重度 AI 工作負載,擺脫昂貴的雲端 API 與 Token 訂閱限制,實現真正的無 Token 稅 (No token tax)、低延遲本地端推論。
AMD 瞄準的其實不是 RTX 5090
看到 128GB Unified Memory,很多人第一時間會拿它跟 RTX 5090 比較。但 AMD 官方的定位其實完全不同。
AI Halo 的主要競爭對手是:
- Apple M4 Pro (代表高階 AI PC)
- NVIDIA DGX Spark (NVIDIA 推出的桌面 AI 開發平台)
根據 AMD 公布的測試數據,在多項生成式 AI 工作負載中,AI Halo 均取得領先表現。這也顯示 AMD 的策略並非打造新的遊戲顯卡,而是直接搶攻本地端 AI 開發市場。

Apple M4 Pro 與 AMD Ryzen AI Halo 生成式 AI 效能對比
在與 Apple M4 Pro 的效能測試中,Ryzen AI Max 在多項多模態任務、圖像生成與語言模型上取得顯著的加速優勢:
- Ace Step 1.5:高達 3.3 倍速度提升
- Ace Step 1.5 XL:高達 7.3 倍速度提升
- Flux Schnell:高達 3.8 倍速度提升
- Flux 2. Klien:高達 4.0 倍速度提升
- Hunyuan 3D 2.1:高達 4.9 倍速度提升
- Qwen Image:高達 3.7 倍速度提升
- Qwen Image Edit:高達 3.9 倍速度提升
- Stable Diffusion XL:高達 4.5 倍速度提升
- Z Image Turbo:高達 4.4 倍速度提升
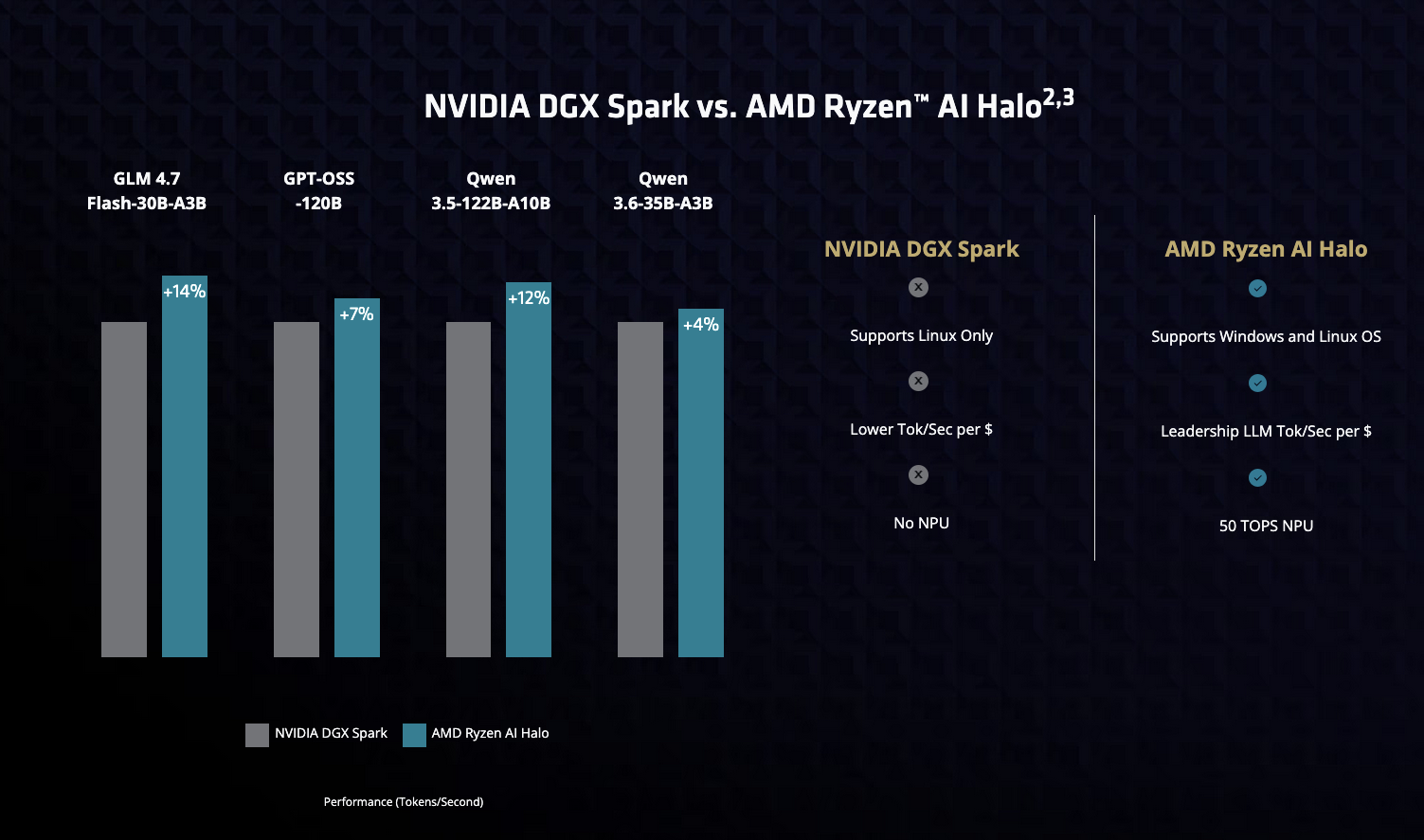
NVIDIA DGX Spark 與 AMD Ryzen AI Halo 大語言模型推論效能對比
而在面對 NVIDIA 針對研究人員與開發者推出的個人 AI 超級電腦 NVIDIA DGX Spark 時,Ryzen AI Halo 在常用開源模型的 Token 輸出速率 (Tokens/Second) 上也表現亮眼:
- GLM 4.7 Flash-30B-A3B:提升 14%
- GPT-OSS-120B:提升 7%
- Qwen 3.5-122B-A10B:提升 12%
- Qwen 3.6-35B-A3B:提升 4%
此外,雙方在軟硬體平台定位上的規格差異也非常明顯:
| 功能與規格對比 | NVIDIA DGX Spark | AMD Ryzen AI Halo |
|---|---|---|
| 作業系統支援 | 僅支援 Linux OS | 支援 Windows 與 Linux 雙系統 |
| 性價比 (Tok/Sec per $) | 較低 | 具備領導地位的 LLM Tok/Sec per $ |
| NPU 內建支援 | 無 NPU | 內建 50 TOPS 算力 NPU |
展望未來:Ryzen AI Max PRO 400 系列
除了目前已經開放預購的旗艦型號外,AMD 也已經公布了下一代的產品藍圖。
預計在 2026 年第三季度,AMD 將與 HP、Lenovo 等 OEM 夥伴合作推出搭載 Ryzen AI Max PRO 400 系列處理器的新世代工作站。新平台將支援高達 192GB 的統一記憶體,並允許將其中高達 160GB 的容量全部分配給 AI 模型使用。這代表著,未來開發者將能夠在本地端工作站上,直接運行高達 3,000 億(300B+)參數量的超大型語言模型。