Gemini 3.5 Live Translate 實測:全新雙向即時語音翻譯與 Live API 開發指南
Google 推出全新的 Gemini 3.5 Live Translate 模型,支援超過 70 種語言的雙向低延遲即時語音翻譯。本文將帶你實測 Google AI Studio 的網頁體驗、了解其運作機制,並提供 Live API 開發範例與 WebSocket 連接設定。
前言
Google 推出了最新的語音翻譯模型 Gemini 3.5 Live Translate。這款模型是專門為即時語音對語音翻譯所設計,支援高達 70 多種語言的雙向翻譯。
與傳統的回合制語音翻譯系統(必須等待講者完全說完一整句話、偵測到停頓後才開始進行語音轉文字、翻譯、最後合成語音)不同,Gemini 3.5 Live Translate 採用了連續串流處理技術。它在講者說話的同時進行即時翻譯,僅保持數秒鐘的極低延遲,並能夠最大程度地保留講者的語氣、語速與音調,實現如同專業口譯員般的流暢對談。
目前此模型已在 Google AI Studio、Google Meet 企業預覽版以及 Android/iOS 的 Google Translate 應用程式中陸續上線。
下面是 Gemini 3.5 Live Translate 的官方展示錄影:
體驗網址:如果你想立即親自動手測試,可以直接前往 Google AI Studio 體驗網址。
核心功能與技術特色
這款模型之所以能在多個應用場景中引發關注,主要得益於以下幾點技術突破:
- 雙向低延遲即時串流:模型能夠即時處理串流音訊,並在幾秒鐘內產生翻譯後的語音。它在「等待上下文以確保翻譯品質」與「立即翻譯以保持同步」之間取得了極佳的平衡,避免了尷尬的長時間停頓。
- 自動語言偵測:輸入多種語言時,不需要手動切換源語言。模型會自動識別高達 70 多種輸入語言,並將其翻譯為你指定的目標語言。
- 聲學特徵保存:翻譯出來的語音不只是冰冷的機器音,它會模擬並保留講者的語氣起伏、速度與情感基調,讓對話感覺更加自然與流暢。
- 抗噪能力與場景整合:在吵雜或難以預測的真實環境(例如街道、會議室)中依然能穩定運作。目前包括 Grab 等企業已在針對司機與乘客的即時通訊進行實測。
- SynthID 數位浮水印技術:模型產生的所有音訊皆會自動織入不可聽覺的 SynthID 浮水印,以防範生成式 AI 語音濫用或傳播不實訊息。
網頁端體驗與使用步驟
若想在 Google AI Studio 中體驗此功能,請參考以下步驟進行操作:
步驟一:前往 AI Studio 後按右側模型選擇
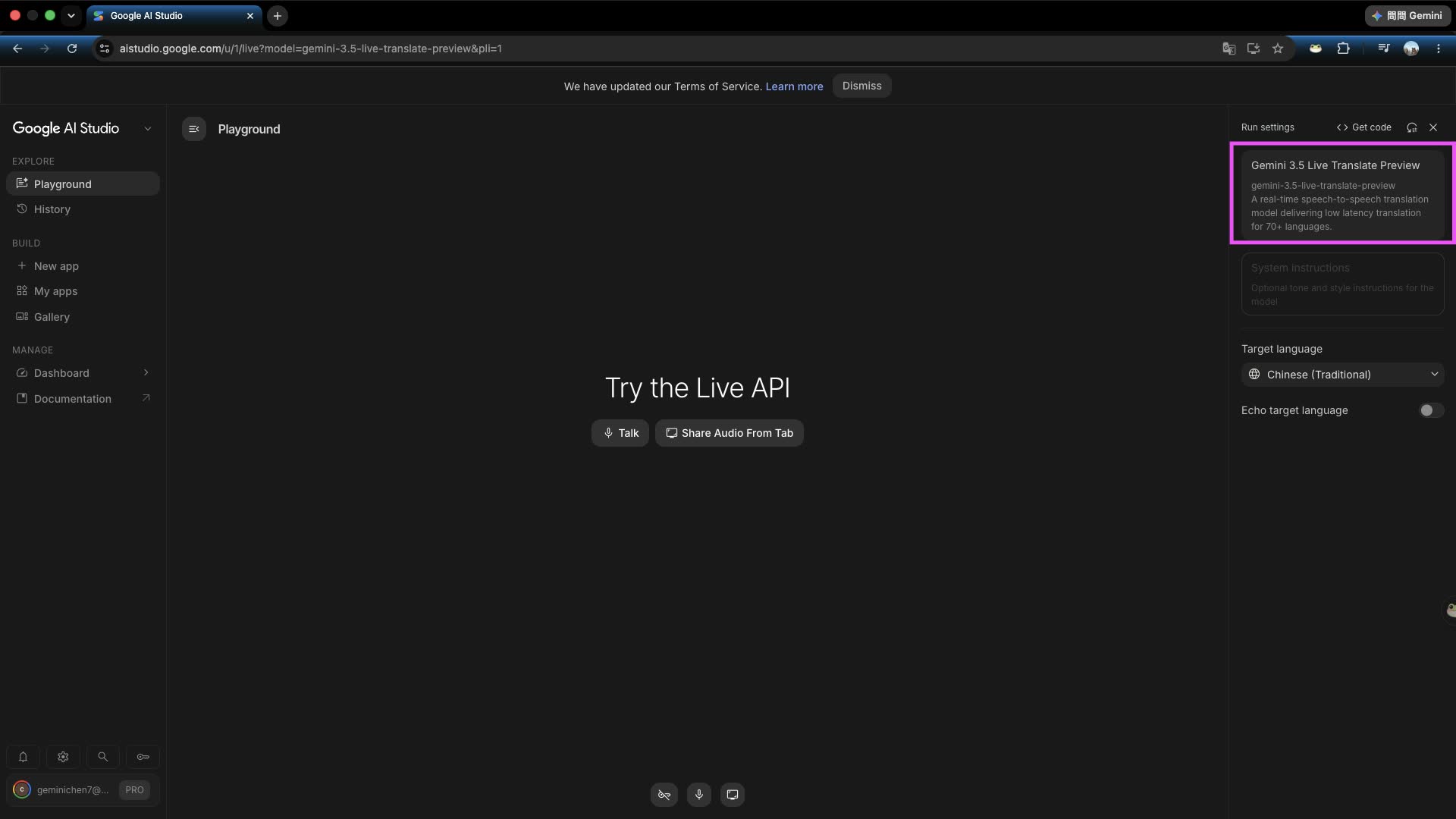
進入 Google AI Studio 頁面,點擊右側的模式與模型選擇區
步驟二:選擇 Audio 就可以找到 3.5 live translate
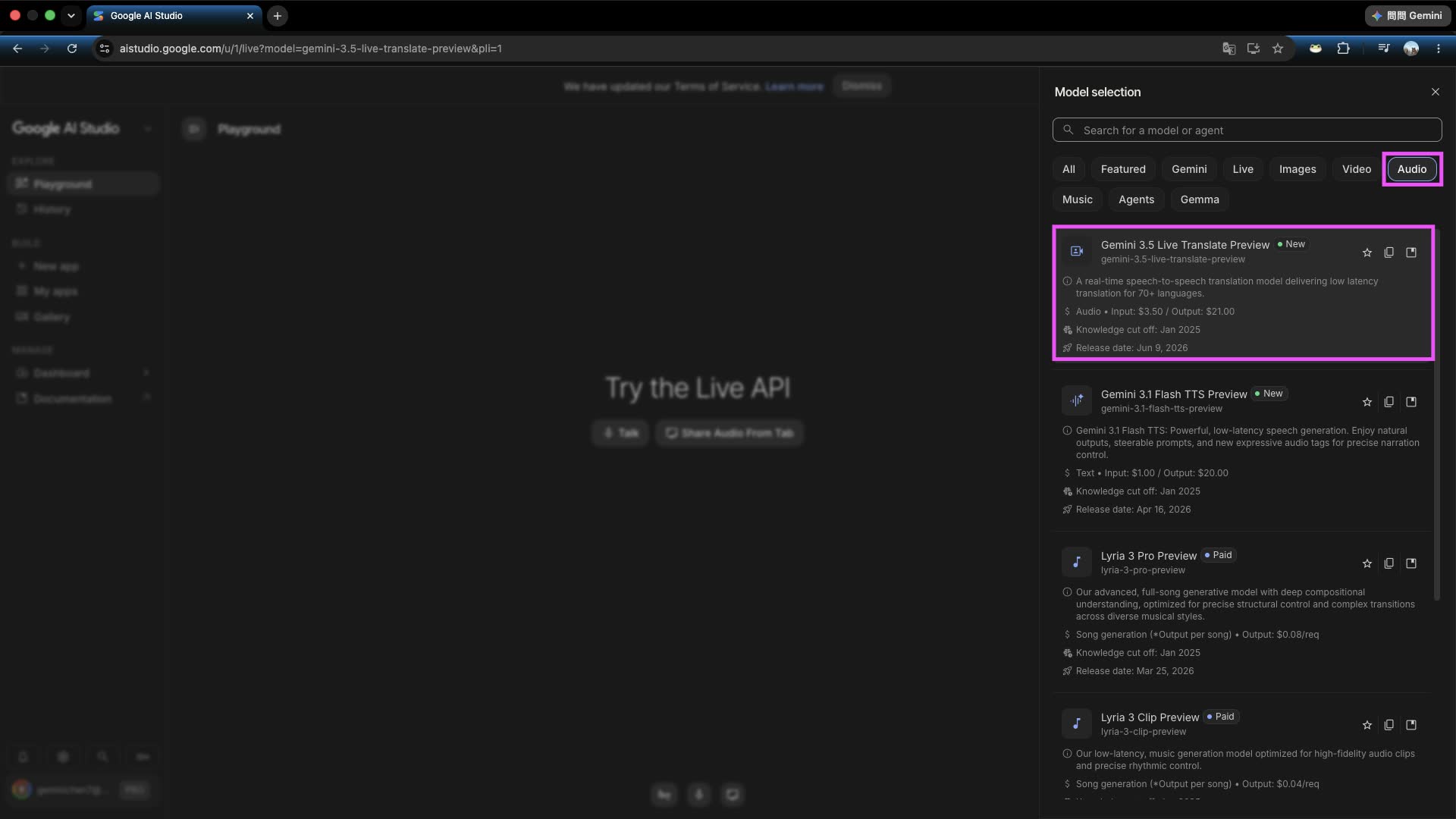
切換至 Audio 頁籤,即可從下拉選單中找到 gemini-3.5-live-translate-preview 模型
步驟三:設定目標語言 (Target Language)

在設定區點擊選擇你的 Target Language(例如繁體中文、英文、日文等)即可開始運作
步驟四:點 Talk 可直接使用麥克風進行即時翻譯或選擇分頁共用音訊
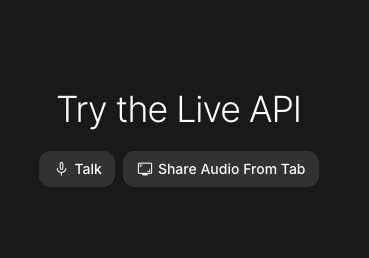
點擊「Talk」按鈕即可直接使用麥克風說話進行即時口譯。若想翻譯其他網頁(例如 YouTube 影片),可選擇「Share Audio from tab」來導入分頁音訊
開發者指南:使用 Gemini Live API 進行即時翻譯
除了網頁端體驗外,Google 也開放了 Live API 供開發者整合。
在使用 Gemini Live API 時,必須理解「線上服務專員 (Conversational Agent)」與「即時翻譯 (Live Translation)」這兩個功能在心理模型與技術運作上的核心差異:
| 功能特性 | 線上服務專員 (Conversational Agent) | 即時翻譯 (Live Translation) |
|---|---|---|
| 角色定位 | 扮演助理,負責聆聽、推理並代為執行指令。 | 擔任口譯員,純粹進行語音到語音的翻譯管道。 |
| 互動模式 | 回合制。依賴暫停偵測、意圖分析與中斷處理。 | 連續串流。講者一邊說一邊翻譯,不需等待發言結束。 |
| 工具與擴充 | 支援 Function Calling、Google 搜尋與系統指令。 | 僅支援翻譯。為保證低延遲,不支援其他工具或外部指令。 |
| 多模態能力 | 完整支援文字、音訊、影片與圖片輸入。 | 僅限音訊輸入,以確保最嚴格的即時延遲時間門檻。 |
| 設定複雜度 | 需設定生成參數、語音種類、工具描述與系統指令。 | 簡化設定。僅需指定目標語言代碼與處理相同語言時的行為。 |
連線與實作範例
以下是使用 Python 初始化用戶端並透過 LiveConnectConfig 連接 Live API 進行即時翻譯的程式碼範例:
import asyncio
from google import genai
from google.genai import types
client = genai.Client()
model = "gemini-3.5-live-translate-preview"
config = types.LiveConnectConfig(
response_modalities=["AUDIO"],
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
translation_config=types.TranslationConfig(
target_language_code="pl", # 設定目標翻譯語言,例如 "pl" 代表波蘭文
echo_target_language=True # 若輸入已是目標語言,是否要重述/回應
)
)
async def main():
async with client.aio.live.connect(model=model, config=config) as session:
print("Session started with translation")
# 開始接收翻譯後的語音串流與文字轉錄
async for response in session.receive():
if response.server_content:
if response.server_content.input_transcription:
print(f"Input transcript: {response.server_content.input_transcription.text}")
if response.server_content.output_transcription:
print(f"Output transcript: {response.server_content.output_transcription.text}")
if response.server_content.model_turn:
for part in response.server_content.model_turn.parts:
if part.inline_data:
audio_data = part.inline_data.data
# 播放或處理接收到的音訊區塊(PCM 格式)
print(f"Received audio chunk ({len(audio_data)} bytes)")
if __name__ == "__main__":
asyncio.run(main())
傳送音訊資料
要將語音輸入傳送至 Live API 進行翻譯,必須以每 100 毫秒 (100ms) 的區塊格式,串流傳送符合規格的 PCM 音訊:
- 輸入音訊規格:16 kHz, 原始 16-bit PCM(單聲道,小端序/Little-Endian)。
- 輸出音訊規格:24 kHz, 原始 16-bit PCM(單聲道,小端序/Little-Endian)。
# 假設 chunk 是你的原始 PCM 音訊位元組資料
await session.send_realtime_input(
audio=types.Blob(
data=chunk,
mime_type="audio/pcm;rate=16000"
)
)
用戶端應用程式的臨時權杖 (Ephemeral Tokens)
在開發行動端或瀏覽器端的即時翻譯應用時,為了避免在客戶端代碼中暴露你的主要 API 金鑰 (API Key),可以使用臨時權杖機制 (v1alpha 版本):
- 必須使用
v1alpha端點。 - 鎖定設定:開發者可在後端伺服器建立權杖時限制
translationConfig。這能確保翻譯參數被鎖定,客戶端無法擅自修改。 - 解除鎖定:若想讓用戶在客戶端自由切換翻譯目標語言,可在伺服器端產生權杖時省略此設定,並宣告
'lock_additional_fields': []。
以下是後端伺服器產生帶有限制的臨時權杖範例:
import datetime
from google import genai
now = datetime.datetime.now(tz=datetime.timezone.utc)
client = genai.Client(
http_options={'api_version': 'v1alpha'}
)
token = client.auth_tokens.create(
config = {
'uses': 1,
'expire_time': now + datetime.timedelta(minutes=30),
'live_connect_constraints': {
'model': 'gemini-3.5-live-translate-preview',
'config': {
'translation_config': {
'target_language_code': 'pl',
'echo_target_language': True
}
}
},
'http_options': {'api_version': 'v1alpha'},
}
)
模型限制與注意事項
儘管 Gemini 3.5 Live Translate 的表現相當優異,但在開發與設計實際產品時,仍需注意以下幾個限制:
!IMPORTANT
- 僅限語音輸入:即時翻譯模式目前僅支援音訊輸入,不支援文字輸入。
- 語音複製的穩定度:在遇到長時間暫停後,系統合成的語音可能會發生變化;或是根據講者最初的發音特徵,可能會誤判並指派錯誤的性別聲音;在多人快速交談的場景下,翻譯語音也可能卡在特定的聲音特徵。
- 語系自動偵測的模糊區:若講者帶有非常重的口音,或是說話時使用極為相似的語系(例如西班牙文與葡萄牙文),偵測系統可能較難精準區分。不過這主要只會影響輸入端的文字轉錄稿,最終翻譯出的語言與內容通常仍是正確的。
- 回音與背景雜音干擾:若輸入音訊中本身就包含目標語言,開啟
echoTargetLanguage: true有可能因為背景噪音或音樂的干擾,在最終生成的音訊中產生失真。
相關連結
- AI Studio 體驗網址:https://aistudio.google.com/u/1/live?model=gemini-3.5-live-translate-preview
- Live API 功能指南:Google AI Studio 官方說明文件
- GitHub 範例專案:google-gemini/gemini-live-api-examples